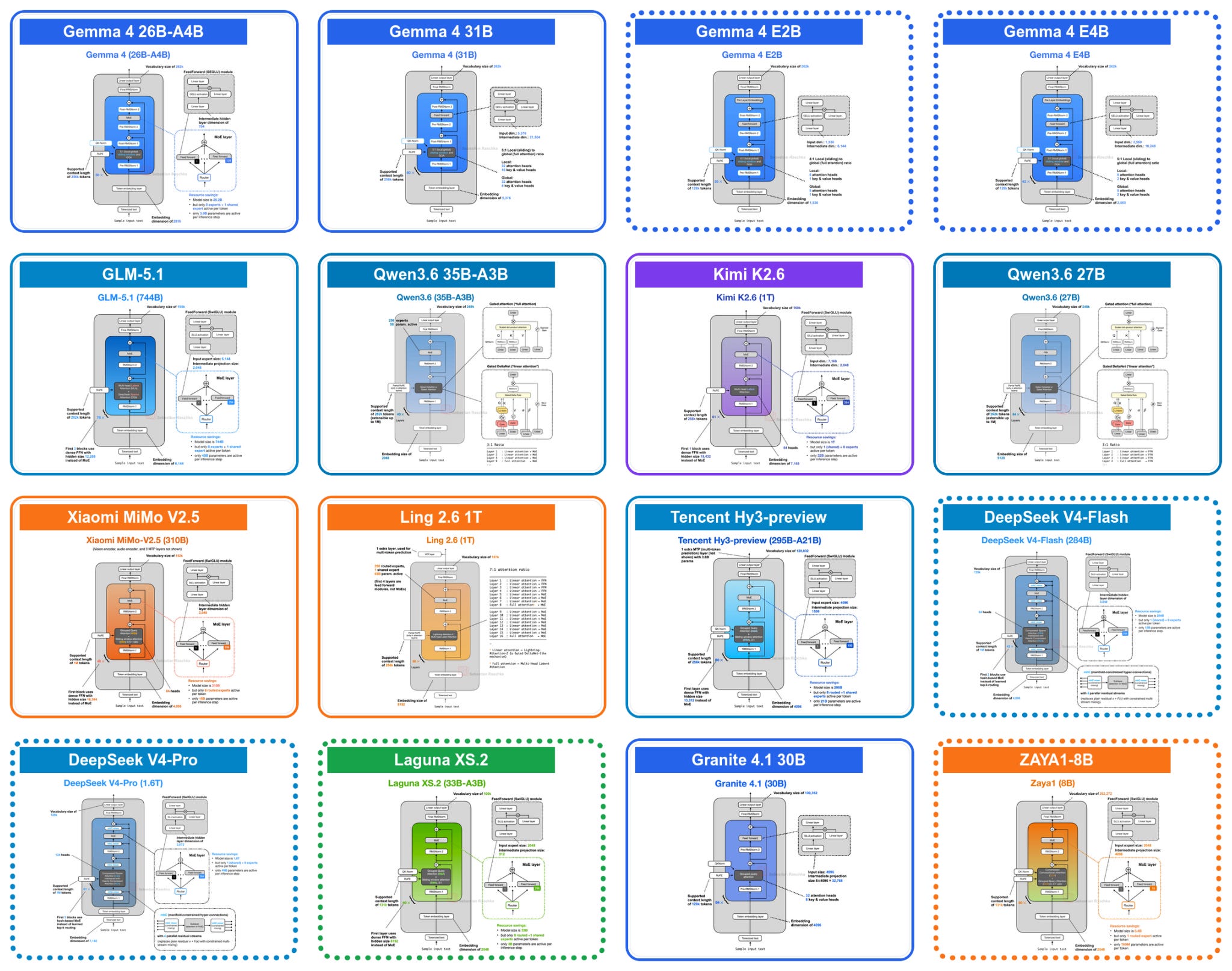
Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed Attention
From Gemma 4 to DeepSeek V4, How New Open-Weight LLMs Are Reducing Long-Context Costs
This post originally appeared in Ahead of AI.
“The basic recipe is still based on the original GPT decoder-only transformer architecture, but many parts are upgraded or replaced, and they get more specialized for longer contexts and more efficient inference.”
After a short family break, I am excited to be back and catching up on a busy few weeks of open-weight LLM releases. The thing that stood out to me is how much newer architectures are focused on long-context efficiency.
As reasoning models and agent workflows keep more tokens around (for longer), KV-cache size, memory traffic, and attention cost quickly become the main constraints, and LLM developers are adding a growing number of architecture tricks to reduce those costs.
The main examples I want to look at are KV sharing and per-layer embeddings in Gemma 4, layer-wise attention budgeting in Laguna XS.2, compressed convolutional attention in ZAYA1-8B, and mHC plus compressed attention in DeepSeek V4.
Most of these changes look like small tweaks in my architecture diagrams, but some of them are quite intricate design changes that are worth a more detailed discussion.