
NVIDIA's AI Engineers: Agent Inference at Planetary Scale and "Speed of Light" — Nader Khalil (Brev), Kyle Kranen (Dynamo)
NVIDIA welcomes AI Engineers with a special pre GTC episode!
This post originally appeared in Latent Space.
“Agents can do three things. They can access your files, they can access the internet, and then now they can write custom code and execute it.”
Join Kyle, Nader, Vibhu, and swyx live at NVIDIA GTC next week! SAIL is also hosting 10-minute AI research interviews onsite at the GTC — hosted by some of our SAIL authors and open to the public. Stay tuned for links to sign up!
The definitive AI Accelerator chip company has more than 10xed this AI Summer:
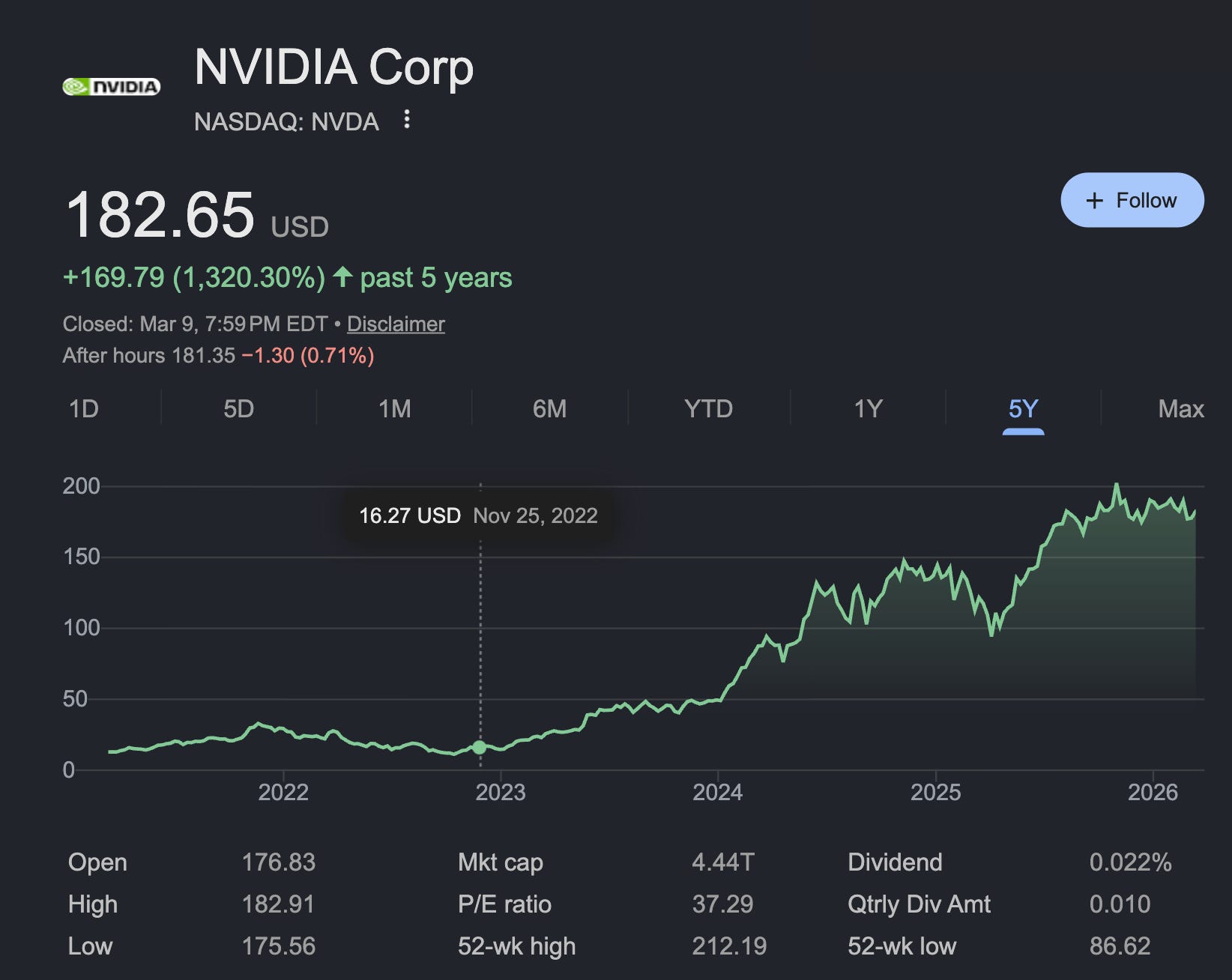
And is now a $4.4 trillion megacorp… that is somehow still moving like a startup. We are blessed to have a unique relationship with our first ever NVIDIA guests: Kyle Kranen who gave a great inference keynote at the first World’s Fair and is one of the leading architects of NVIDIA Dynamo (a Datacenter scale inference framework supporting SGLang, TRT-LLM, vLLM), and Nader Khalil, a friend of swyx from our days in Celo in The Arena, who has been drawing developers at GTC since before they were even a glimmer in the eye of NVIDIA:

Nader discusses how NVIDIA Brev has drastically reduced the barriers to entry for developers to get a top of the line GPU up and running, and Kyle explains NVIDIA Dynamo as a data center scale inference engine that optimizes serving by scaling out, leveraging techniques like prefill/decode disaggregation, scheduling, and Kubernetes-based orchestration, framed around cost, latency, and quality tradeoffs.
We also dive into Jensen’s “SOL” (Speed of Light) first-principles urgency concept, long-context limits and model/hardware co-design, internal model APIs (https://build.nvidia.com), and upcoming Dynamo and agent sessions at GTC.
Full Video pod on YouTube
Keep reading with a 7-day free trial
Subscribe to SAIL Media to keep reading this post and get 7 days of free access to the full post archives.
 | A guest post by
|