Latest open artifacts (#21): Open model bonanza! Gemma 4, DeepSeek V4, Kimi K2.6, MiMo 2.5, GLM-5.1 & others. On CAISI's V4 assessment.
An eventful month with one flagship release after another
This post originally appeared in Interconnects.
“The progress of its releases is remarkable, with 2.5 Pro being neck and neck with other flagship models such as Kimi K2.6 and GLM-5.1 in both benchmarks and real-world usage.”
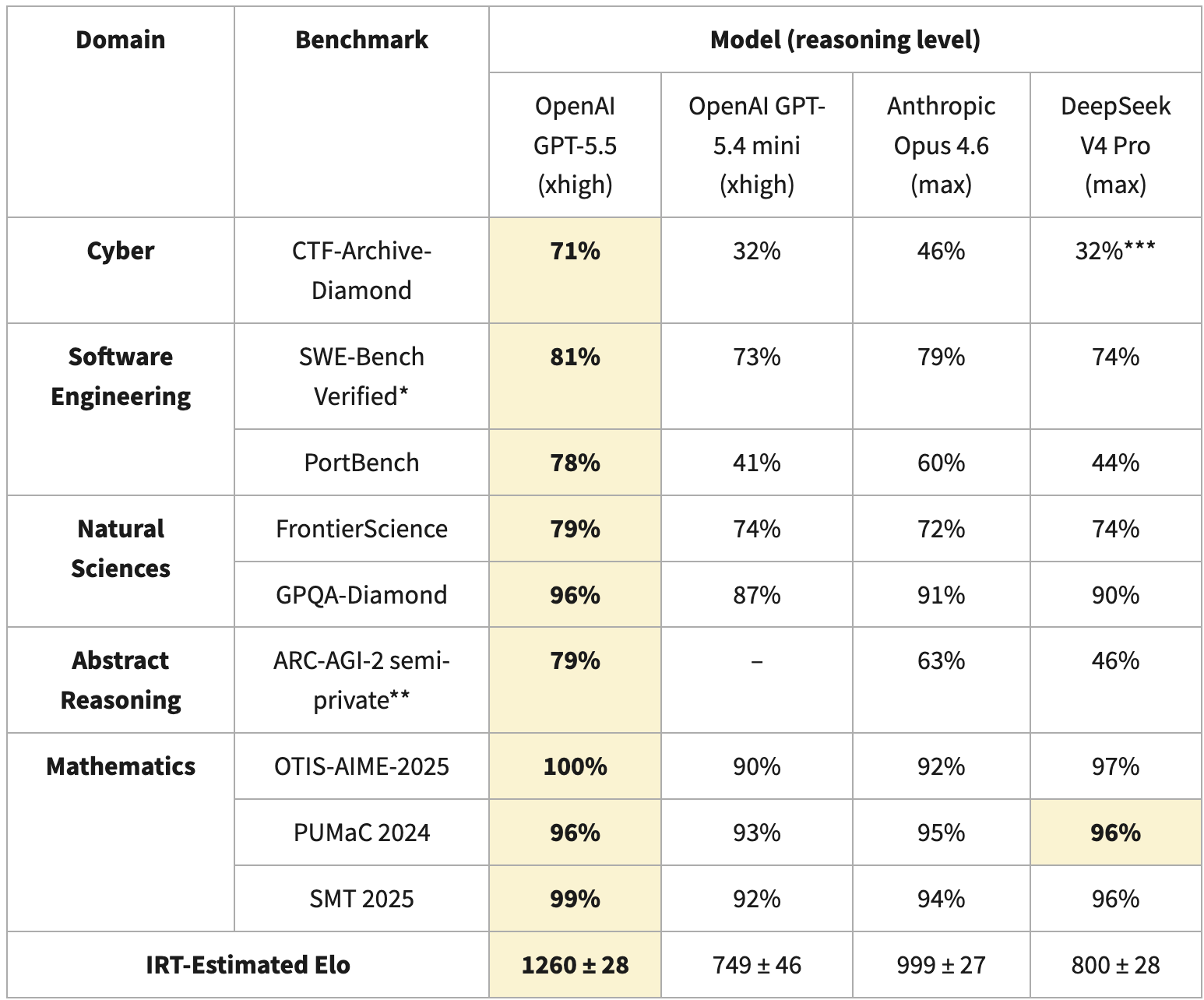
This month was packed, with all open frontier labs, including DeepSeek, releasing new models. The latter prompted an evaluation by the Center for AI Standards and Innovation (CAISI), which has evaluated open models and their risks in the past. Their result is that open models lag behind the American frontier, with the gap becoming wider over time:

For the report, they calculate an Elo score based on Item Response Theory, which is commonly used to compare different models, even when they were tested on a different set of benchmarks. For V4, CAISI used nine different benchmarks: