
How open model ecosystems compound
Further reflections on China's high-participation, open-first AI ecosystem.
This post originally appeared in Interconnects.
“This sort of engine drives incredible progress in performance per dollar, and when combined with a more open development process, could drive China to have a higher ceiling in the long-term AGI race.”
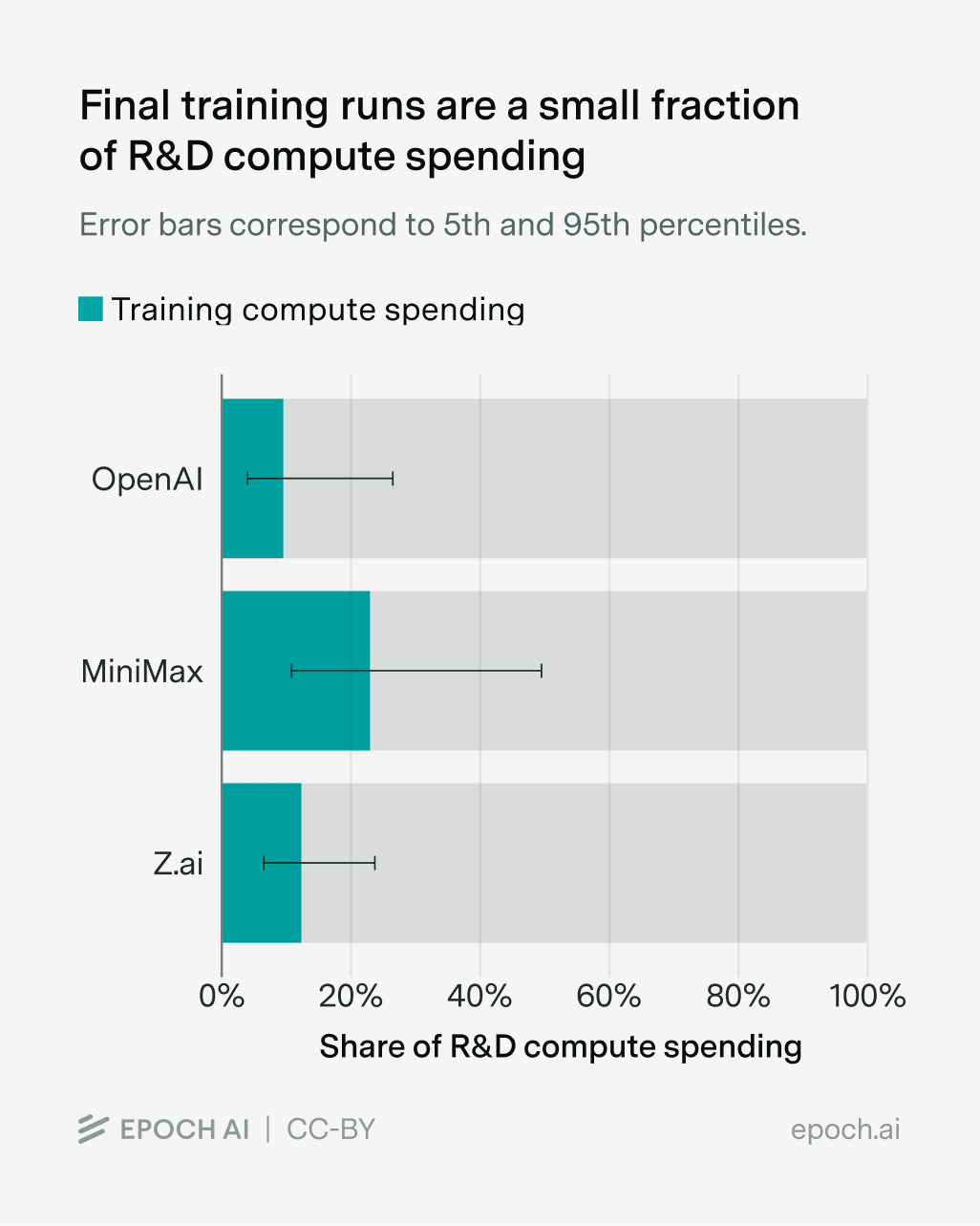
Most of the compute to build a leading frontier model comes from R&D costs, rather than the compute to train the final, big model end-to-end. In an ecosystem like China, where all the leading players are open, this creates a potential meaningful advantage in cost structures that’ll let labs keep building longer than outside observers would expect.
There are two recent pieces of research, one from Ai2 documenting the development of Olmo 3 and one from Epoch AI studying public documentation of costs from various frontier labs, that put the estimate of compute spent on R&D rather than the final model at about 80% (with meaningful error bars).
In a world where research and development is most of the compute, the Chinese system is designed around quickly learning from your peers and avoiding double-spending research compute — or infra effort. It’s far from perfect, but it’s the closest analog to the OSS ecosystem that one can get for building LLMs. The public discussion of AI has always emphasized that the models are expensive in a way that naturally lets passive readers think this is compute just dedicated to the artifact — as we saw with DeepSeek V3.