
A Visual Guide to Attention Variants in Modern LLMs
From MHA and GQA to MLA, sparse attention, and hybrid architectures
This post originally appeared in Ahead of AI.
“MLA is a preferable attention mechanism for DeepSeek not just because it was efficient, but because it looked like a quality-preserving efficiency move at large scale.”
I had originally planned to write about DeepSeek V4. Since it still hasn’t been released, I used the time to work on something that had been on my list for a while, namely, collecting, organizing, and refining the different LLM architectures I have covered over the past few years.
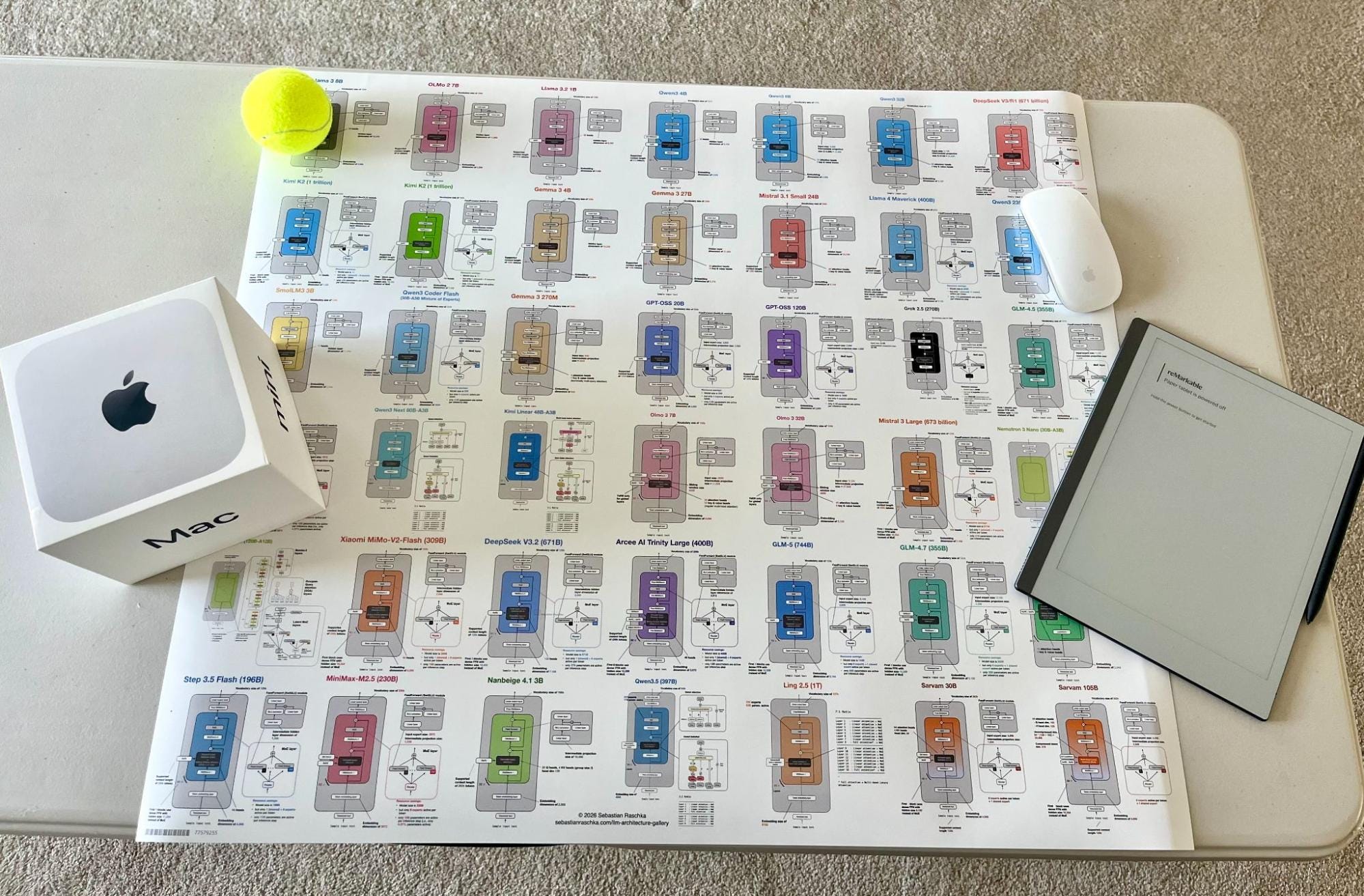
So, over the last two weeks, I turned that effort into an LLM architecture gallery (with 45 entries at the time of this writing), which combines material from earlier articles with several important architectures I had not documented yet. Each entry comes with a visual model card, and I plan to keep the gallery updated regularly.
You can find the gallery here: https://sebastianraschka.com/llm-architecture-gallery/

After I shared the initial version, a few readers also asked whether there would be a poster version. So, there is now a poster version via Redbubble. I ordered the Medium size (26.9 x 23.4 in) to check how it looks in print, and the result is sharp and clear. That said, some of the smallest text elements are already quite small at that size, so I would not recommend the smaller versions if you intend to have everything readable.
Alongside the gallery, I was/am also working on short explainers for a few core LLM concepts.